Kondah MouadUnpacking the Apache ActiveMQ Exploit (CVE-2023–46604)Recently, there was a critical vulnerability in Apache ActiveMQ, CVE-2023–46604, with a CVSS v3 score of 10 out of 10, which certainly…·8 min read·Nov 5, 2023----
Kondah MouadStep-by-Step Implementation of Generative Pre-Trained Transformers (GPT)In this post, we explore the implementation of a small GPT model using Keras and Tensorflow.·6 min read·Aug 10, 2023----
Kondah MouadCVE-2023–34035: Improper AuthorizationIn this post, I will share how I discovered CVE-2023–34035, a CVE Misconfiguration in the famous Spring Security Project.·3 min read·Jul 30, 2023----
Kondah MouadinGeek CultureSpring Data JPA, Spring Data R2DBC & Hibernate ReactiveData Persistence allows applications to persist and retrieve information from non-volatile storage. In this environment, applications must…·15 min read·Sep 11, 2022----
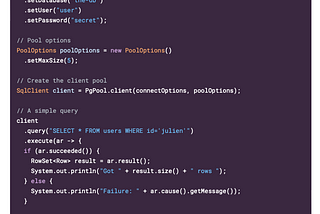
Kondah MouadinGeek CultureVert.x - Reactive PostgreSQL ClientData Persistence — The Reactive Approach·12 min read·Sep 2, 2022----
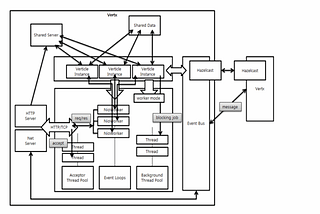
Kondah MouadinGeek CultureSmashing Vert.x coreUnless you’ve been living in a cave for the past few years, you’ve probably heard of reactive programming. There are so many frameworks out…·25 min read·Jul 26, 2022----
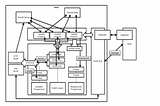
Kondah MouadinGeek CultureIstio, eBPF and RSocket Broker: A deep dive into service meshIntroduction·14 min read·Jun 28, 2022--1--1
Kondah MouadinGeek CultureA deep dive into StrimziStrimzi is an open-source project that provides container images and Kubernetes operators for running Apache Kafka on Kubernetes.·21 min read·Jun 22, 2022----
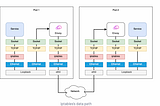
Kondah MouadinGeek CultureRSocket, Modern Microservices CommunicationRSocket is fully reactive bi-directional binary communication protocol that tries to overcome few of the limitations of HTTP1 and HTTP2 by…·20 min read·May 5, 2022--1--1